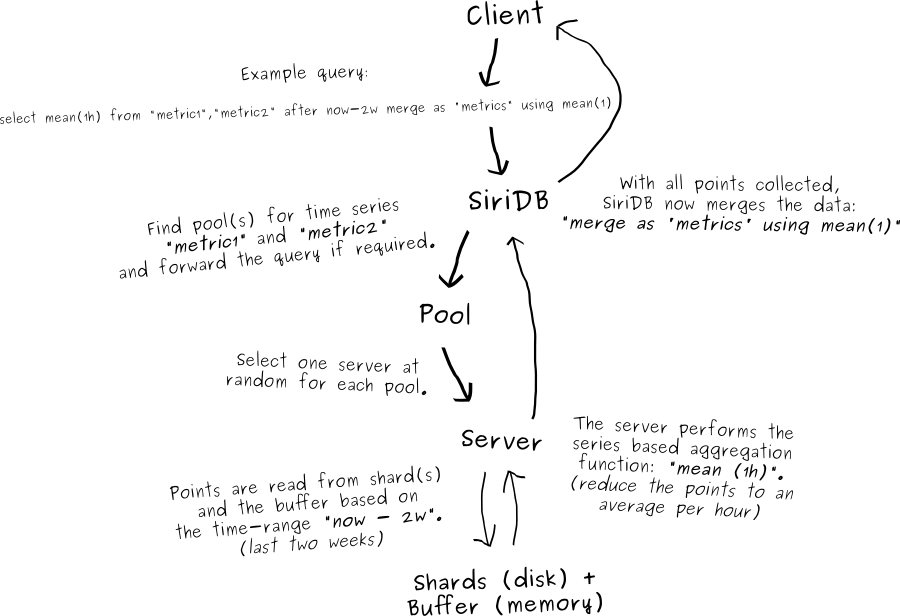
Query data
When a SiriDB server receives a query it forwards the query to the correct pool(s) if required. In case a pool has two available servers, one is chosen randomly.
The server in the pool determines which chunks are required to answer the query and loads them from the shards. Finally, it checks if the buffer contains points which are applicable to the requested time-range and adds them as well. The points will then be sent to the server which received the original request. That server in turn sends the final result to the client.
SiriDB supports aggregation and filter methods which can save much network traffic to the client. When possible the aggregation and filter methods are performed immediately after reading the time series data in a pool. This way less data needs to be sent back to the server responsible for handling the query. This also spreads the CPU load for the aggregation across multiple pools.